


- 30 Mar, 2026
- Künstliche Intelligenz
- Sicherheit
- By Stefan Antonelli
Security Audit mit Claude Opus: So findest du Schwachstellen in deiner App
Einen professionellen Security Audit für eine App oder Website durchführen – klingt nach teuren Spezialisten und langen Wartezeiten. Mit dem richtigen Prompt und dem passenden KI-Modell bekommst du einen strukturierten, tiefgehenden Sicherheitscheck in wenigen Minuten. Wie das geht, zeige ich in diesem Beitrag.
Warum Claude Opus für Security-Aufgaben?
Nicht jedes KI-Modell eignet sich gleich gut für sicherheitskritische Analysen. Claude Opus 4.6 von Anthropic hat sich hier als besonders stark erwiesen. Das Modell denkt in sogenannten Reasoning-Schritten – es geht also nicht nur oberflächlich über den Code, sondern arbeitet sich durch Zusammenhänge, Abhängigkeiten und potenzielle Angriffsvektoren, die Standard-Scanner schlicht nicht finden.
Der entscheidende Unterschied: Während automatisierte Tools bekannte Muster suchen, denkt Claude wie ein Angreifer. Es prüft Logikfehler, Umgebungskonfigurationen und Edge-Cases, die in keiner CVE-Datenbank stehen.
Was kann mit dem Prompt analysiert werden?
Der Ansatz ist flexibel. Im Video als Beispiel dient ein Astro-Projekt – ein Static Site Generator auf Basis von React und Next.js. Aber der Prompt funktioniert genauso für:
- Web Apps (React, Vue, Angular, Next.js)
- Backend-Code (Python, Node.js, Go, etc.)
- Astro- oder andere Static-Site-Templates
- API-Schichten und Microservices
Der einzige Unterschied: Der Prompt muss leicht auf den jeweiligen Kontext angepasst werden. Ansonsten bleibt die Struktur gleich.
Der Security-Audit-Prompt
Das ist der Prompt, den ich im Video verwendet habe. Er folgt dem modernen Ansatz: klares Ziel, präzise Aufgabe, strukturiertes Output-Format.
You are a senior application‑security engineer tasked with performing a one‑time,
comprehensive security review of the codebase before it goes live. Use the reasoning
mode to explore unconventional attack vectors, edge‑cases and subtle logic flaws that
standard scanners might miss.
## Task
Scan the entire codebase for:
- Injection flaws (SQL, NoSQL, command, template, LDAP, XSS, etc.)
- Broken authentication & session management
- Sensitive data exposure (secrets, configs, logs, API keys)
- XML‑external‑entity (XXE) and deserialization issues
- Broken access control (IDOR, privilege escalation, missing checks)
- Security misconfigurations (debug modes, open directories, CORS, headers)
- Use of vulnerable or outdated dependencies (CVEs in package‑lock files)
- Insufficient logging & monitoring
- CSRF, SSRF, open redirects, and business‑logic flaws
- Any other OWASP Top 10‑2021 or ASVS‑L2 weakness.
For each finding, output:
- File path & line numbers (or function/module name)
- Vulnerability type (with CWE ID if applicable)
- Brief description of why it is a problem
- Proof‑of‑concept / exploit sketch (how an attacker could trigger it)
- Severity rating (CVSS 3.1 base score & vector) and impact/likelihood justification
- Remediation recommendation (code change, config tweak, library update, etc.)
- References (OWASP, CVE, MITRE ATT&CK, etc.)
Prioritize the list by severity and provide a short executive summary:
- Number of critical/high/medium/low findings
- Overall risk rating for the MVP
- Immediate "must‑fix" items before launch
- Suggested timeline for remediation.
If the codebase uses any third‑party services or APIs (e.g., payment gateways, auth
providers), note any trust‑boundary or credential‑handling concerns.
Conclude with a checklist of items to verify in a subsequent automated CI/CD security
scan (e.g., SAST rules, dependency‑check, container‑image scanning).
## Output format
Use markdown with a table for the findings and a separate section for the executive
summary and checklist. Keep the language precise, technical, and actionable.So sieht das Ergebnis aus
Claude liefert nach dem Audit eine strukturierte Markdown-Tabelle mit allen gefundenen Schwachstellen, jeweils mit:
- CVSS-Score (numerisches Schwerebewertungsschema)
- CWE-ID (standardisierte Schwachstellen-Klassifikation)
- Proof-of-Concept – wie ein Angreifer die Lücke konkret ausnutzen könnte
- Direkte Remediierungsempfehlung – was genau geändert werden muss
Ergänzt wird das durch eine Executive Summary mit einer Übersicht der kritischen, hohen, mittleren und niedrigen Befunde sowie einem konkreten Zeitplan zur Behebung. Am Ende folgt eine CI/CD-Checkliste für automatisierte Folge-Scans.
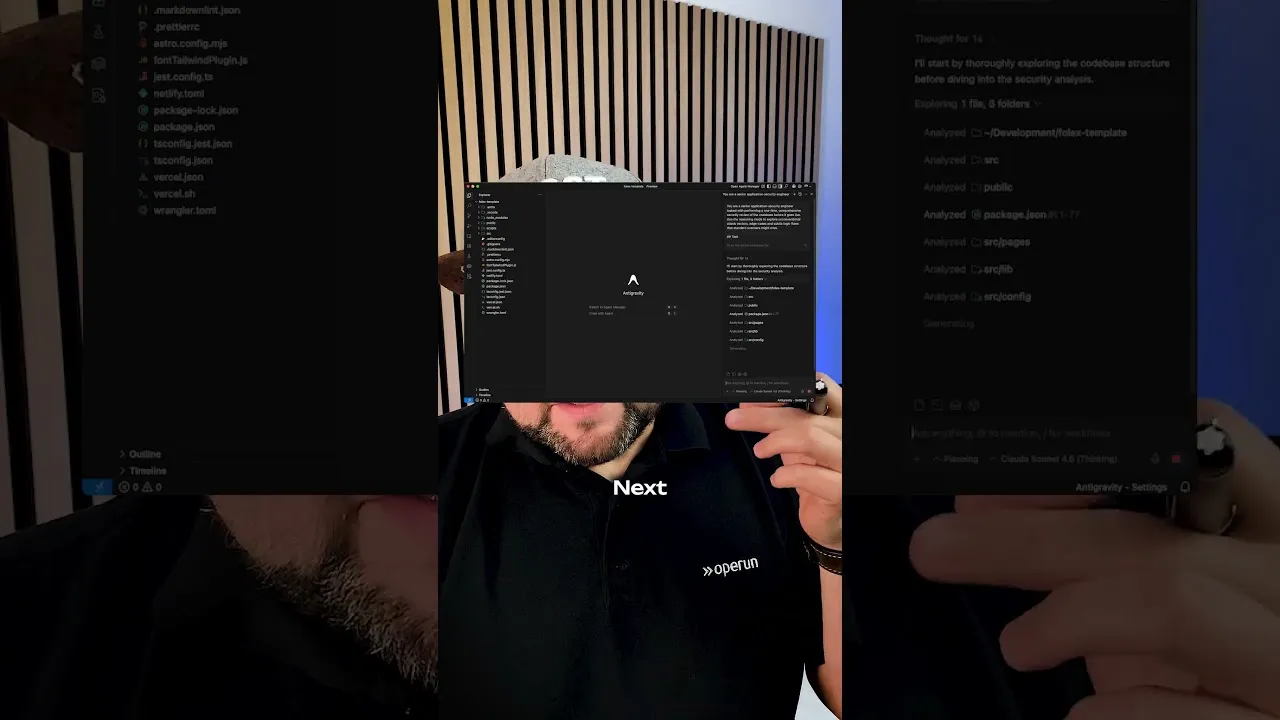
Welches Setup funktioniert am besten?
Im Video wird Google Antigravity verwendet – Googles agentische Entwicklungsumgebung – zusammen mit einem Astro-Projekt. Antigravity hat dabei einen entscheidenden Vorteil: Es kann die komplette Codebase als Kontext übergeben, inklusive aller Dateien, Abhängigkeiten und Konfigurationen.
Das Setup in der Kurzfassung:
- Projekt in einem Editor (z.B. Google Antigravity) öffnen
- Claude Opus 4.6 als aktives Modell auswählen
- Prompt einfügen und die komplette Codebase als Kontext übergeben
- Ergebnis auswerten und priorisierte Findings sukzessive abarbeiten
Fazit
Ein KI-gestützter Security Audit ist kein Ersatz für einen professionellen Pentest vor einem großen Launch – aber er ist ein exzellentes Werkzeug für die Entwicklungsphase. Wer regelmäßig prüft, ob Konfigurationen sauber sind, keine Secrets im Code landen und keine bekannten Muster-Schwachstellen existieren, spart sich teure Überraschungen später.
- AI
- KI
- Claude
- Claude Opus
- Security
- Sicherheit
- Security Audit
- Prompt Engineering
- Vibe Coding